
Dimensions and Measures: A SQL Perspecitive
I thought I'd kick this off gently. I remember going through Boot Camp after joining Tableau and learning about dimensions and measures. And I remember finding the descriptions rather confusing.
I don't recall the precise phrasing, but it went something like this:
Dimensions are usually those fields that cannot be aggregated; measures, as its [sic] name suggests, are those fields that can be measured, aggregated, or used for mathematical operations.
Or this:
Measures are the result of a business process event... Dimensions are reference variables that give context to measures.
I don't really mean to criticize these definitions, but to a database guy, they seem rather imprecise. For someone with a little SQL know-how, the actual definition is both crisp and helpful in understanding what Tableau really does under the covers—this helps predict what actions in the UI will do, so you don't just blindly drag-and-drop until things look right.
The rest of this post is a crisp explanation of dimensions and measures for someone who knows a little SQL.
Tableau does a lot of things, but at its core—or what I like to think of as its core—it's an aggregation engine: you tell it how to slice-and-dice your data and what aggregates to apply, and it does so. Then there is some visualization on top. That's nice, too.
What this means is that so long as we confine ourselves to "simple" things, and our data are in a table T, then Tableau is going to produce a query that looks like:
SELECT some stuff FROM T GROUP BY some other stuff
When I say "simple", I mean that we're going to confine ourselves to dragging fields into the Columns, Rows, and Marks shelves:
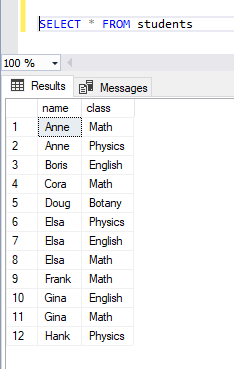
To illustrate, I swiped some highly confidential student records from the nearby college and dumped them into SQL Server. Here they are:
And now the meat of the post: Tableau's rule for generating a SQL query from the collection of items on each of the shelves. It's very simple—don't blink:
- If a field is used as a dimension, then it's added to the GROUP BY and SELECT clauses.
- If a field is used as a measure, then it's only added to the SELECT clause, with the appropriate aggregation applied.
That's it. The order doesn't matter. The exact shelf doesn't matter. All we care about is whether each field is a dimension or a measure.
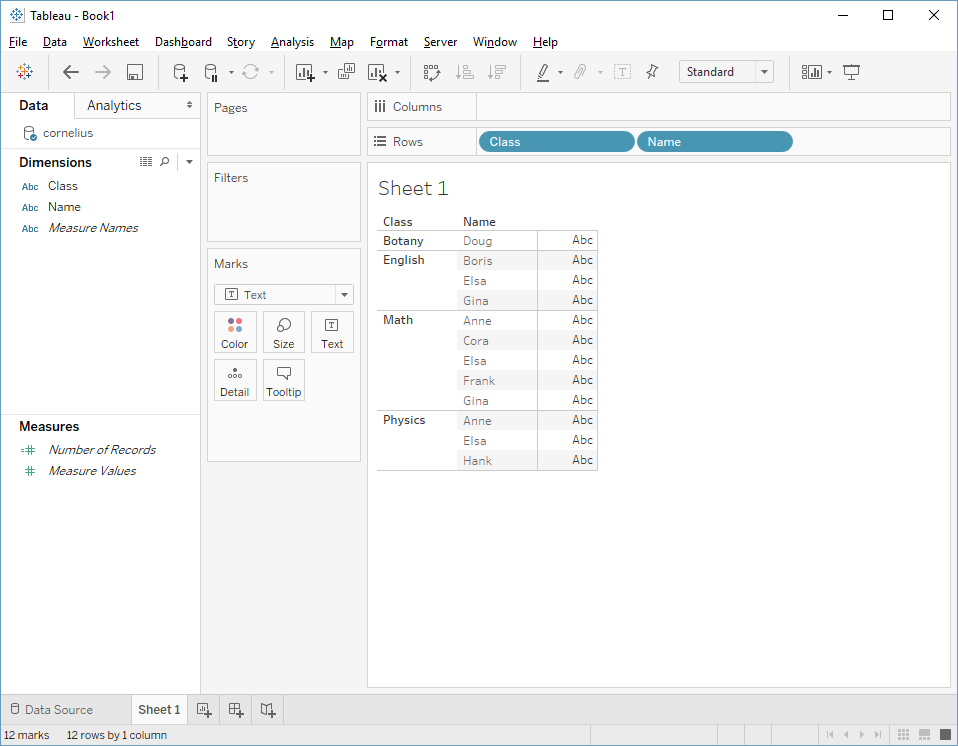
Let's try this out. We'll just use the rows shelf, and drag out both Class and Name as dimensions. According to our rules, we should then generate:
SELECT class, name FROM students GROUP BY class, name
Let's see what happens. First, here's what things look like in Tableau:
This looks promising. Now let's look at the query that was generated. There are various ways to do this, including digging through Tableau's logs with the Tableau Log Viewer. I'm going to use the SQL Server Profiler to get the query.
I won't give all the Profiler details. Tableau issues a bunch of little metadata queries, but if we dig a tiny bit, we find the main course:
SELECT [students].[class] AS [class], [students].[name] AS [name] FROM [dbo].[students] [students] GROUP BY [students].[class], [students].[name]
And there we have it. A few more characters, but exactly the query we predicted. I've color coded these examples to make it easier to line up the fields.
But what are those "Abc"s? Well, Tableau wants to put a mark for each value that it's calculating, and we haven't told it what data to show, so it uses "Abc" as a placeholder. We can improve our viz a little and get rid of these by moving the Name to "Text" shelf:
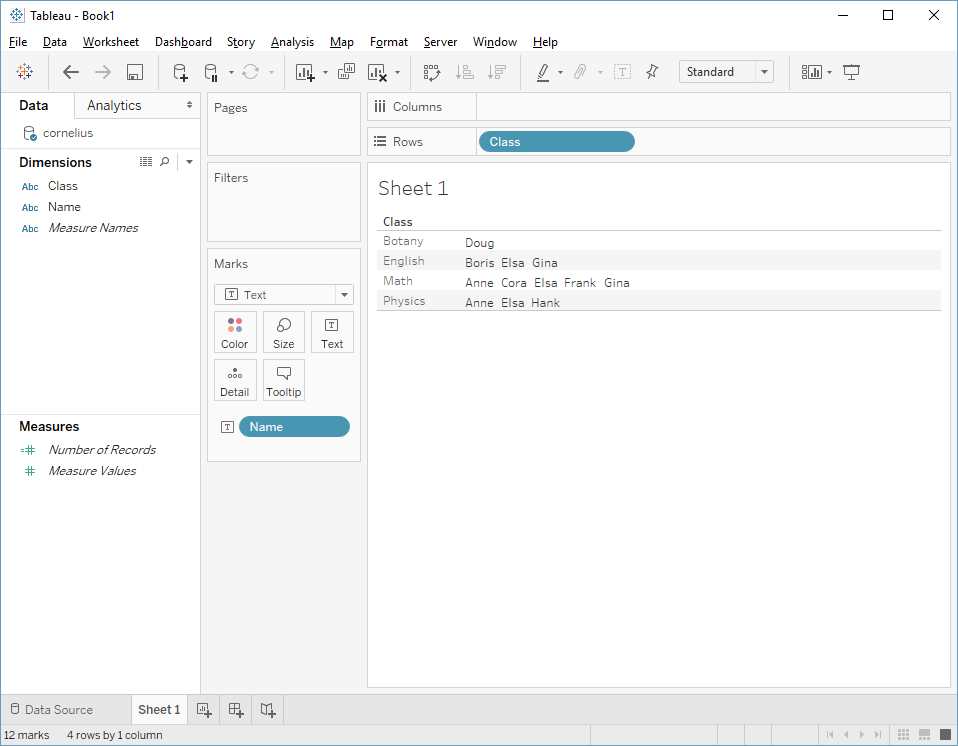
A visualization guru might scoff at this. But I'm not a visualization guru. What we care about is the query this generates. And although the visualization has changed, the underlying query doesn't: we're still using both Name and Class as dimensions, and each unique pairing of these values shows up once in the viz.
Let's try to use this knowledge to direct the viz we get. Let's say that we want to know how many classes each student is taking. In SQL, we might write:
SELECT COUNT(class), name FROM students GROUP BY name
How do we get this in Tableau? Reviewing our rules, we see that we should leave Name a dimension, and make Class a measure with COUNT as its aggregation.
Let's try it. Here I've put Name on Rows, and COUNT(Class) on Text:
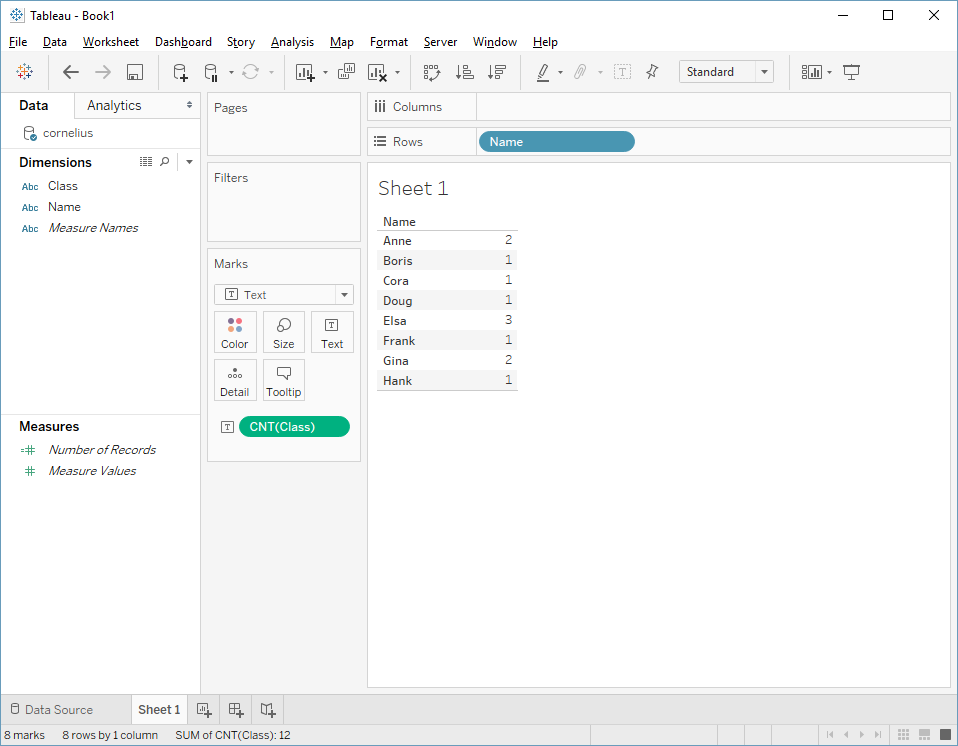
That looks right: we have one mark for each distinct name, that mark is the count of classes. Just to confirm, let's go to the SQL:
SELECT COUNT_BIG([students].[class]) AS [cnt:class:ok], [students].[name] AS [name] FROM [dbo].[students] [students] GROUP BY [students].[name]
Spot on!
Again, we can make a better viz—say, a bar chart—but rest assured, it's just another way of presenting the same data from the same query:
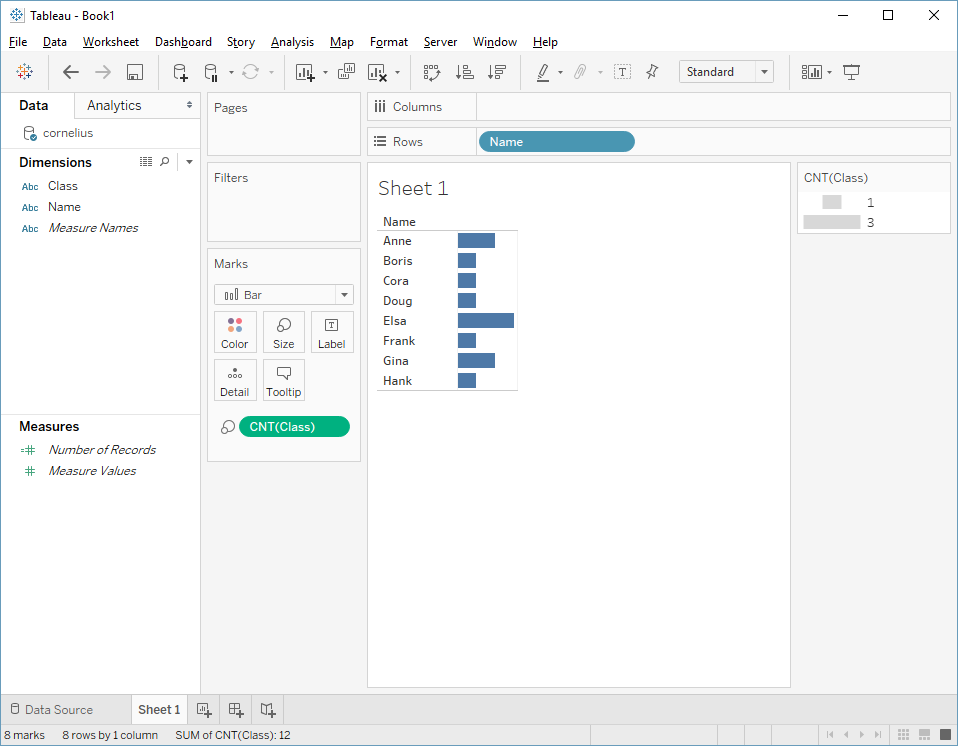 (I always knew Elsa was an overachiever.)
(I always knew Elsa was an overachiever.)
To recap, dimensions and measures are really very simple. Dimensions are the things that you group by; they show up in both the GROUP BY and SELECT clauses of the underlying query. And measures are the things you're aggregating; they never show up in the GROUP BY clause, only aggregated in the SELECT clause.
Cheers,
-Isaac
